Autoscaling explained: Why scaling your site is so hard

Scaling up is a natural first step to prepare for heavy website traffic. But if you disregard the difficulty of autoscaling, you risk failure during your busiest and most business-critical sales. Using an infographic, everyday language & plenty of analogies, here’s an explainer of why scaling a website is anything but easy.
“Just scale up!” says the ecommerce director. “It can’t be that hard.”
You’re probably here to help explain to management why “just scaling up” is harder than it seems—or to understand it better yourself.
In an ideal world, websites could scale infinitely and on demand, accommodating whatever traffic the internet throws their way. Trendy buzzwords like “autoscaling” make this sound simple and automatic.
But scaling servers is no trivial task. And scaling your web application is even harder.
Using everyday language, plenty of analogies, and a sweet infographic, here's our take on why scaling your website is so darn difficult.
Table of contents
- What does scalability & server scaling mean?
- What is autoscaling?
- Why is website scaling so hard? An analogy
- Infographic showing the difficulty of server scaling
- The cost of server scaling: Vertical vs. horizontal scaling
- The problem with autoscaling ecommerce sites
- How over-reliance on website scaling can let you down
- Summary
First things first:
Behind every website is a physical server (or group of servers, known as a server farm). Servers provide computing power to serve data to website visitors when they open your website in their browsers.
Scalability describes the ability of a system to grow while managing the increased use that comes with growth. To serve more visitors, web applications need increased computing power from the servers and need all the applications’ components to scale as well.
Server scaling describes adjusting the computing power of servers, usually to increase power by “scaling up”. This can be done either by scaling vertically or horizontally. Vertical scaling involves replacing the server with a larger, more powerful one. Horizontal scaling (sometimes called “scaling out”) means adding several servers and combining their totaled computing power.
Put simply, autoscaling means automatically adjusting computing power according to load. It’s “auto”, as in automatic, and “scaling”, as in increasing computing power.
With autoscaling set up right, your server capacity should automatically increase as traffic levels rise. And as traffic decreases, so will your server capacity, saving you cloud computing costs during off-peak times.
When Facebook first implemented autoscaling, for instance, engineer Qiang Wu shared that the company had a 27% reduction in energy usage during low traffic hours and a 10-15% overall decline in energy use.
Autoscaling lets you build elasticity into your systems, reducing the need to monitor and predict traffic levels. It saves money on the quiet days, and preserves performance on the big ones.
Or at least that’s the hope.
This is what autoscaling does. But it’s a bit more complicated than that. And as anyone who hosts a high traffic website knows, autoscaling (and server scaling in general) isn’t the “cure-all” it sounds like.
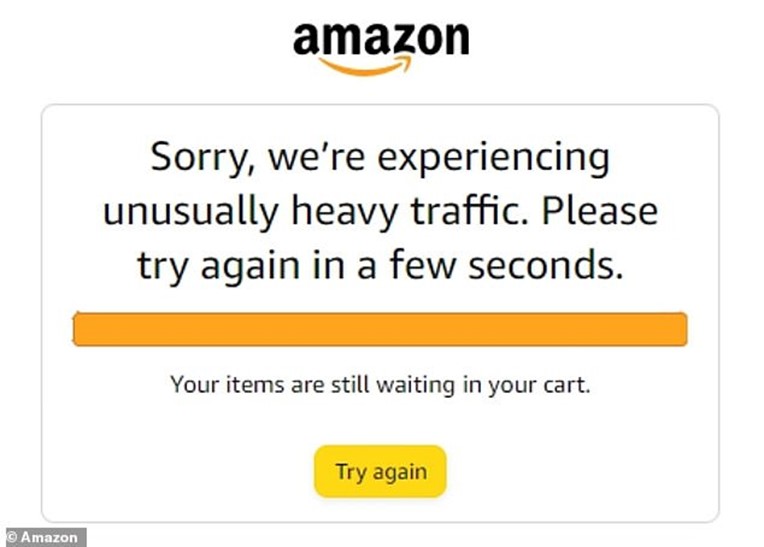
Even Amazon, a pioneer in autoscaling services through AWS, still crashes and faces performance issues on its biggest days.
Let’s look at why.
When you scale up your servers, you expect website performance to stay stable. The point of scaling up is to keep the website functioning just as well with 10 visitors per minute as 100 visitors per minute.
But the devil is in the details—scaling servers doesn’t mean all parts of the website can scale equally well. The mechanics behind scaling your website make it difficult and complex to maintain performance under increased demand.
This explains why Urs Hölzle, Google’s first vice president of engineering, says:
"At scale, everything breaks."
According to Paul King, a data scientist who’s worked at Facebook, Quora, and Uber, that’s because your web application runs into four main problems when you try to scale it:
- The search problem
- The concurrency problem
- The consistency problem
- The speed problem
To illustrate this example, we’ll take the analogy of using a phone book to find someone’s phone number.
Let’s start with the phone numbers of the people who live in your building. There might be 10-20 names listed, each with an accompanying phone number.
You can quickly find the name and phone number of whoever you need to reach. And all the information fits on a single sheet of paper that can be easily distributed in the building.
RELATED: How to Avoid the Website Capacity Mistake Everyone Makes
The search problem describes the difficulty of finding the information you need in a sea of data. The bigger the data set, the more intensive it is to find what you’re looking for.
So, imagine we’re now growing our phone book to cover 1 million city residents. It would take hours to scan through an unorganized list of names and phone numbers.
Organizing the names in some way—alphabetically, geographically, etc.—is a strategy to deal with the search problem. But if you’ve ever tried this, you’d know it would still take longer than scanning a single page list of names.
Get peace of mind on your busiest days with your free guide to managing ecommerce traffic peaks

The concurrency problem describes the difficulty of making data available to several people, programs, or resources simultaneously.
In our analogy, if all 1 million people wanted to find someone’s phone number at the same time from 1 phone book, there would be a massive line. You’d never get to make your call!
Creating extra copies of the phone book (called “replication”) could help ease the concurrency problem. As could delivering these extra copies to city residents (called “distribution”). But as you’ll see, these lead to issues with the remaining two problems.
The consistency problem describes the difficulty of dealing with constantly updated data whose updates need to be reflected to the people, programs, or resources using that data.
Now what happens when people change phone numbers? The printed, distributed phone books are out of date as soon as they’re printed. Now you need to update all 1 million copies.
If you collect all the phone books, it will take time to replace them, and then you’ll have an availability problem. The data won’t be consistently accessible. You could change them out one at a time. But then data will be inconsistent across the city. You could publish addendums of all recent changes (called “change logs”). But then every time anyone wants to check a phone number, they must scan the addendum(s) first, adding time to the entire process.
The speed problem describes the increasing difficulty of handling more and more requests or transactions.
We just saw how adding change logs increases the time needed to look up a number. Now imagine a new phone company enters the market and offers a bargain phone plan. Suddenly, lots of people at once change their phone numbers. So many numbers are changing that the printing process needs to speed up. Delivery services are inundated. Trash cans are filled with old phone books.
All in all, speeding things up takes an already complex situation and makes it downright chaotic.
All these problems afflict ecommerce websites, too.
It’s easy enough to build a website with a few items. But when you have thousands of products, you need advanced search functions and meaningful categories to help customers find what they need. The more products, the more effort this takes from your application. You run into the search problem.
Most open-source ecommerce platforms are built around inventory truthfulness, prioritizing consistency over concurrency. As we’ve just seen with the phone book analogy, you can’t have both at the same time.
And when popular sales like Black Friday drive website traffic through the roof, the speed problem rears its ugly head, explaining why mega-retailers like Amazon, H&M, and Walmart have seen their websites crash.
As Paul King writes:
"The basic goal of a database is to maintain the illusion that there is only one copy, only one person changes it at a time, everyone always sees the most current copy, and it is instantly fast."
Systems engineers use hundreds of interlocking algorithmic tricks to try to maintain this illusion. But when your website needs to truly—and worse, quickly—scale to growing demand, the fabric holding together this illusion stretches and tears. Your visitors experience this in real time, as your website slows and eventually crashes.
RELATED: The Cost of Downtime: IT Outages, Brownouts & Your Bottom Line
“Our systems struggled with the traffic spikes. We first tried to handle these issues with autoscaling, but it rarely reacted fast enough to keep up with the sudden surge in users.”
ATSUMI MURAKAMI, CHIEF OF INNOVATION
Here's an infographic we've put together outlining the problems you face when trying to scale your web application.

We know that scaling up your whole web application is incredibly complex. But the more website visitors increase, the complexity builds exponentially—and so can the costs.
To understand why vertical scaling (scaling up) is so expensive, let’s compare the engines of the Ferrari 812 Superfast with the Ford Focus.
The Ferrari’s motor produces a maximum of 789 horsepower. That’s a lot of power! But, you pay a premium for such a high-performing car. Ferrari takes on a lot of costs designing, engineering, and producing a high-quality engine capable of such power. Top-notch materials. Incredibly efficient design. You get the picture. The $315,000 price tag reflects these costs.
The Ford Focus engine pumps out a respectable 160 horsepower. It’s no Ferrari 812 Superfast. But at a price of $19,000, it’s also far more economical. You’d need 5 Ford Focus engines to reach the output of the Ferrari, but this would cost $95,000, or over 3 times less than the Ferrari engine. If you could connect the 5 Ford engines, you’d realize the same power at a fraction of the cost.
When vertical scaling requires increasingly higher-end servers, costs increase exponentially.

What’s more, if you do need to swap out one server for a higher-end one, you’ll need downtime to make the switch. That’s why vertical scaling doesn’t mesh well with autoscaling. Every time you need to scale up or down, you’d incur downtime.
Horizontal scaling (scaling out) is the cheaper of the two when it comes to hardware costs. Data center costs can be higher because of increased space, cooling, and power usage. And licensing fees can increase as you have more nodes, or groupings of servers, to license. Depending on your licensing structure, you might end up needing annual licenses for servers even if you only use them for one or two days in the year.
However, the hidden costs come with the dedicated expertise needed to set up and maintain the autoscaling and application scaling. Many IT teams consist of devoted DevOps engineers handling the technical details. If Amazon’s Prime Day failure tells us anything, it’s that it’s incredibly challenging to autoscale a website under heavy load.
Early improvements are easier to find and give better performance. But the more you try to squeeze out of your application, the less benefit any changes will have. More bugs appear as the code becomes more complex. Every time you find one bug, there will be a new bottleneck.
Many bugs aren’t “bugs” until there’s high load on your system. For example, your IT team might shard data to improve performance, so that all product whose SKU code start with A-M is in server 1 and N-Z is in server 2. If you have one really hot item, all the users will be hitting that one database server, causing it to fail earlier than expected.
So even though horizontal scaling gives more flexibility for autoscaling and has lower administrative costs than vertical scaling, resource costs can skyrocket.

Scaling ecommerce sites is anything but easy. Setting up autoscaling is a worthwhile process, but relying on autoscaling alone when you traffic surges suddenly is expensive at best, and risky at worst. There's three key reasons why:
- Autoscaling is complex: It's extremely difficult and sometimes impossible to automatically scale all components of your tech stack. This means that even if you scale your servers, traffic still overloads hard-to-scale bottlenecks like databases, inventory management systems, third-party services like payment gateways, or performance-intensive features like dynamic search or a “recommended for you” panel.
- Autoscaling is reactive: Because traffic levels are hard to predict and autoscaling takes time to kick in, your systems likely won’t be ready in the critical moment they’re needed. The reactivity of autoscaling is one of the main reasons major ecommerce sites still crash when traffic suddenly spikes.
- Autoscaling is expensive: If you overcome the challenges of autoscaling's complexity and reactivity, you still have to deal with its costs. To deal with the unpredictable spikes in traffic, systems with automatic scaling typically overprovision resources to remain scaled for peak load for the duration of an event—driving huge costs. To successfully scale third-party services for peak load, you may need to increase subscription levels or change providers. And to set up and maintain autoscaling, you'll need real DevOps experts, and a lot of their time.
These challenges to successful scaling explain why IT business expert Eric David Benari has said:
“Performance has very little to do with database tuning and a lot more to do with reducing database requests.”
RELATED: 3 Autoscaling Challenges & How To Overcome Them With A Virtual Waiting Room
“Autoscaling doesn’t always react fast enough to ensure we stay online. Plus, it’s very expensive to autoscale every time there’s high traffic. If we did this for every traffic spike, it would cost more than double what we pay for Queue-it. So Queue-it was just the better approach, both in terms of reliability and cost.”
MIJAIL PAZ, HEAD OF TECHNOLOGY
A virtual waiting room is a bolt-on tool that lets your existing site perform like one that’s purpose-built for high traffic without re-architecting. It controls what autoscaling can't: the flow of online visitors.
The solution addresses all three of the challenges to successful autoscaling outlined above:
- It lets you control the rate at which traffic hits your site or key bottleneck, allowing you to tune traffic flow to match the max throughput of your least scalable system—be it your payment gateway, inventory database, or login.
- It gets triggered as soon as traffic surges, removing the need to predict or react to spikes in traffic by automatically redirecting excess visitors off your infrastructure.
- It prevents overprovisioning by allowing you to scale to a fixed point, then operate at maximum capacity without the risk of failure; and as a bolt-on, easy-to-use solution, it saves on the set-up and maintenance costs of autoscaling.
Virtual waiting rooms work by automatically redirecting visitors to an online queue that sits off your infrastructure when traffic exceeds the thresholds you’ve set. Visitors see a branded waiting room like the one below, with their number in line, their estimated wait time, and a progress bar. From here, they're flowed back to your site at the rate it can handle in a fair, controlled order.
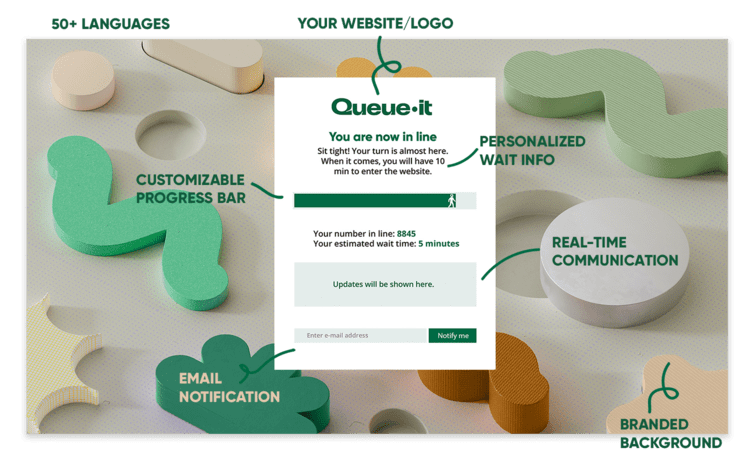
RELATED: How Queue-it's Virtual Waiting Room Works [For Developers]
With Queue-it, you can keep your systems optimized for typical traffic levels and customer behavior, while still having the agility and confidence to embrace new trends and handle the unexpected.
“Queue-it’s a great bolt-on piece of infrastructure, completely dynamic to our needs. The virtual waiting room made much more sense than re-architecting our systems to try to deal with the insanity of product drops that take place a few times a year.”
TRISTAN WATSON, ENGINEERING MANAGER
Picture this:
It’s Cyber Five at Walmart and Office Depot.
All hands are on deck for what’s set to be the largest week of online shopping in U.S. history.
War rooms are filled with technicians monitoring dashboards. Teams are checking competitors’ pricing. Marketing has several campaign tricks up their sleeve.
But when traffic comes streaming to the websites, they falter. Both show temporary error pages like these:
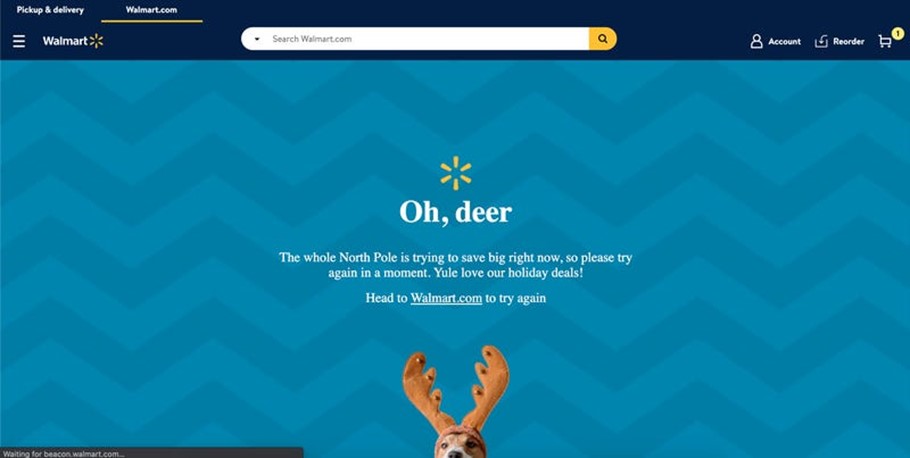
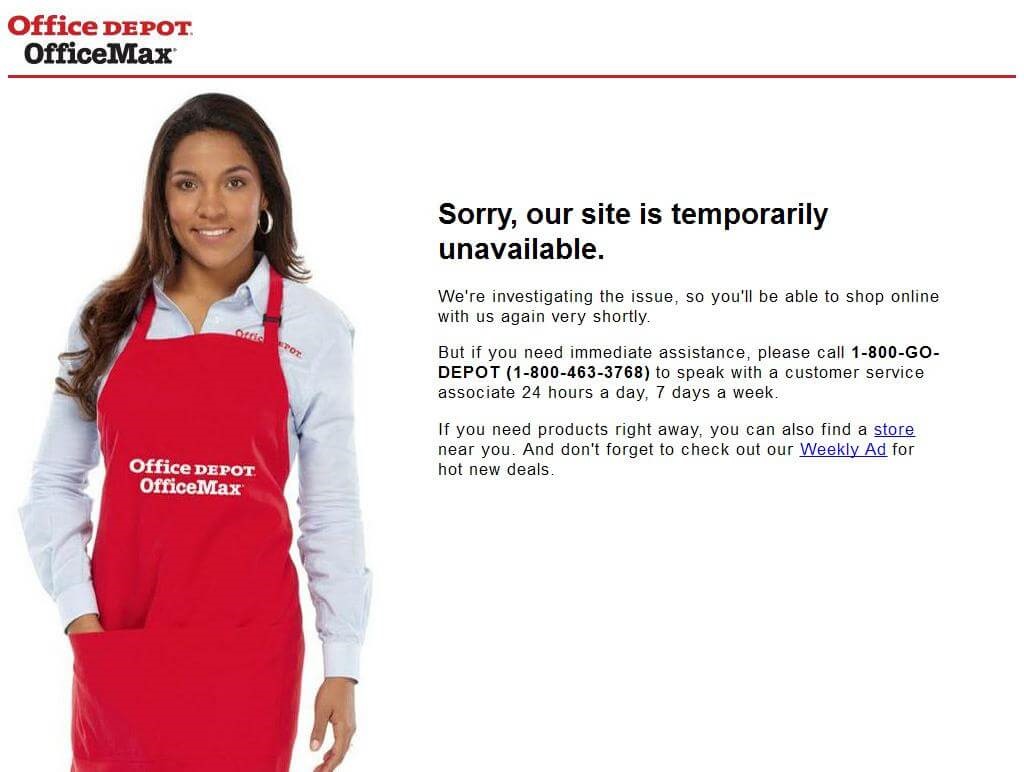
Walmart and Office Depot were among over 40 retailers that faced issues during 2021’s Cyber Five. Office Depot suffered a particularly bad almost 3-hour outage on Cyber Monday, forcing them to extend sales to the next day.
Estimates put the costs of these crashes in the millions. They break down trust and send customers straight into the hands of competitors.
RELATED: The Cost of Downtime: IT Outages, Brownouts & Your Bottom Line
What went wrong?
It’s not that the websites are too bulky. Rather, it’s that traffic simply spiked too high too suddenly. Queue-it data shows traffic on Black Friday, on average, is 3x that of a normal day in October.
When customers are all rushing to nab Cyber Five deals at once, they end up overwhelming the site. And despite these major retailers using autoscaling, bottlenecks elsewhere in the user journey produce errors and bring them crashing down.
In other words, despite attempts to scale up to prepare for the sale, performance bottlenecks took down 40+ major online retailers during their most business-critical days of the year.
- Scaling up servers is one step you should take to prepare your website for increased demand.
- Vertical scaling (upgrading to higher-end servers) costs increase drastically once you get to higher levels.
- Horizontal scaling (connecting many smaller servers) is cheaper in terms of hardware costs but brings immense complexity in combining all the servers into a unified system that requires specialized—and expensive—personnel to manage.
- Autoscaling can help you handle changing traffic levels, but doesn’t help if traffic surges too suddenly or bottlenecks elsewhere in the user journey are overwhelmed.
- Scaling your website involves much more than just increasing server capacity, but when you scale your website you run into problems of search, concurrency, consistency, and speed.
- Server scaling does not address website bottlenecks like payment gateways. It takes a holistic strategy to build performance into a web application.
- Disregarding how difficult it is to scale servers and websites will put you at risk for failure during your busiest and most business-critical sales.
- Virtual waiting rooms complement autoscaling to reduce risks and save costs when traffic spikes suddenly.
Scaling up your website is a natural first step in handling growing demand. But understand there are limits. Server scaling and autoscaling are but one tool in your crash prevention toolkit.
Thinking you can simply “scale up” and handle infinite amounts of users without addressing bottlenecks is one of the most common website capacity mistakes.
And it’s a mistake that can cost your company millions.
A virtual waiting room controls what autoscaling and other crash-prevention tactics can’t: the flow of online visitors.
It complements autoscaling, enabling you to protect your site against sudden spikes, safeguard key bottlenecks, and ensure scaling costs don’t get out of control. And as a bolt-on tool, the virtual waiting room doesn’t require you to re-architect systems for high-traffic events that only occur a few times a year.
Queue-it is the market-leading developer of virtual waiting room services, providing support to some of the world’s biggest retailers, governments, universities, airlines, banks, and ticketing companies.
When Ticketmaster, The North Face, Zalando, Cathay Pacific, and The London School of Economics need to control their online traffic, they turn to Queue-it.
Book a demo today to discover how you can complement autoscaling with a solution that saves both your website and your bottom line.
(This blog has been updated since it was written in 2019).